Video-Browser: Towards Agentic Open-web Video Browsing
3Beijing Academy of Artificial Intelligence, 4Hong Kong Polytechnic University
Abstract
To bridge this gap, we present Video-BrowseComp, a challenging benchmark comprising 210 questions tailored for open-web agentic video reasoning. Unlike prior benchmarks, Video-BrowseComp enforces a mandatory dependency on temporal visual evidence, ensuring that answers cannot be derived solely through text search but require navigating video timelines to verify external claims. Our evaluation of state-of-the-art models reveals a critical bottleneck: even advanced search-augmented models like GPT-5.1 (w/ Search) achieve only 15.24% accuracy. Our analysis reveals that these models largely rely on textual proxies, excelling in metadata-rich domains (e.g., TV shows with plot summaries) but collapsing in metadata-sparse, dynamic environments (e.g., sports, gameplay) where visual grounding is essential. As the first open-web video research benchmark, Video-BrowseComp advances the field beyond passive perception toward proactive video reasoning.
Video-Browser Agent
To tackle the challenges of open-web agentic video research, we propose Video-Browser, an agentic framework composed of three specialized modules sharing a global memory:
- Planner: Acts as the cognitive controller, decomposing user queries into sequential sub-tasks and generating search queries based on interaction history.
- Watcher: Functions as a high-efficiency filter and localizer using a Pyramidal Perception mechanism. It progressively prunes the search space through Semantic Filtering (Stage I), Sparse Localization (Stage II), and Zoom-in (Stage III) to identify and decode relevant visual evidence without overwhelming computational costs.
- Analyst: Synthesizes the final answer by reasoning over the accumulated multimodal evidence and the query context.
This architecture enables Video-Browser to actively interrogate video timelines and cross-reference dispersed evidence, achieving a 71.8% relative improvement over state-of-the-art search-augmented models (26.19% vs 15.24% accuracy).
Examples

Figure 1: Examples of questions and tasks in Video-BrowseComp.
Dataset Statistics
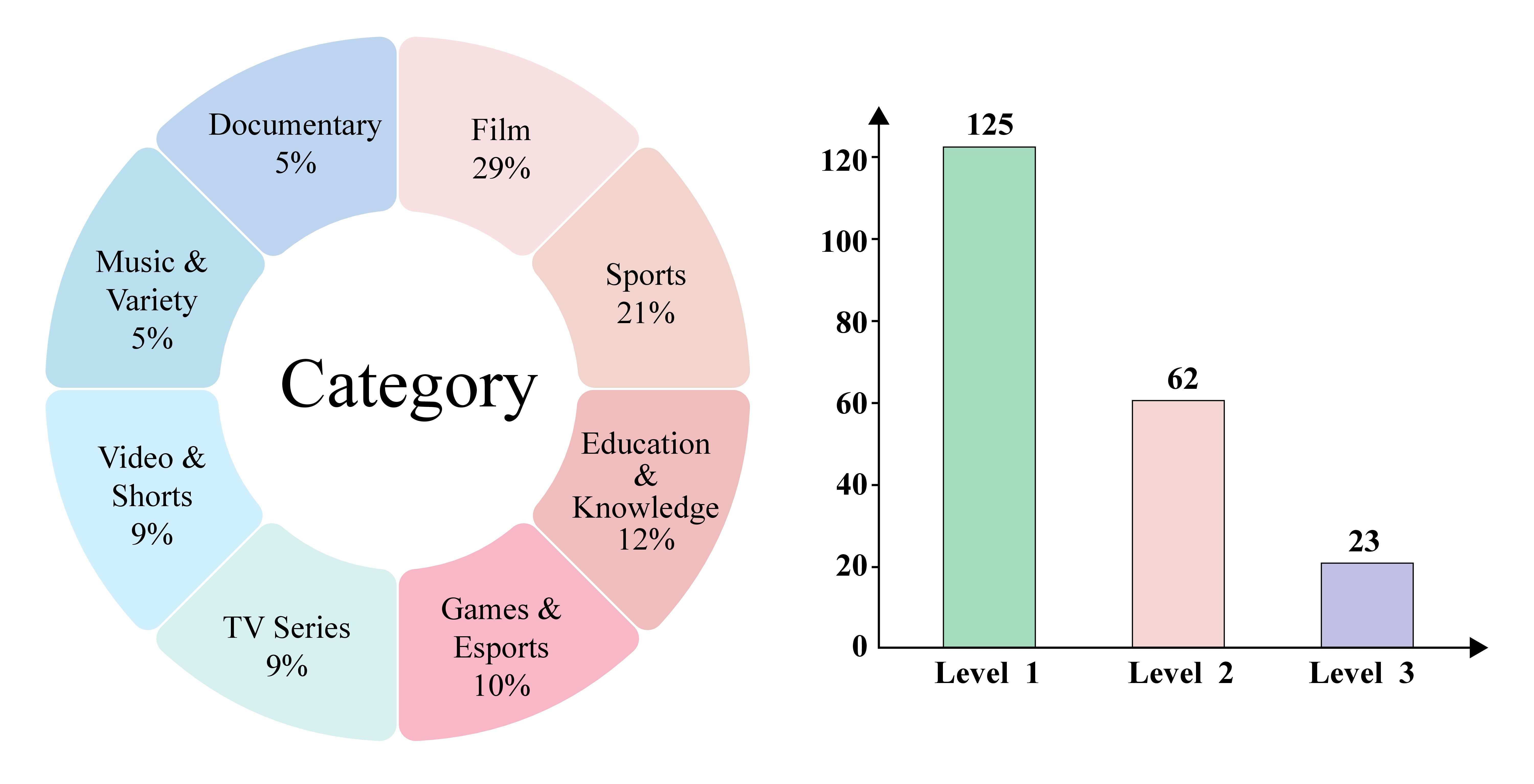
Figure 2: Distribution of video categories and difficulty levels.
Leaderboard
We evaluate state-of-the-art models on Video-BrowseComp. The accuracy (%) is reported for Overall (OA) and three difficulty levels (Level 1, Level 2, Level 3).
| Model | Overall Acc (%) | Level 1 (%) | Level 2 (%) | Level 3 (%) | Calibration Error (%) |
|---|
Submission Guide
We welcome submissions of new models to the Video-BrowseComp leaderboard! To submit your results, please follow these steps:
- Run your model on the Video-BrowseComp benchmark available on Hugging Face.
- Prepare a JSON file containing your model's predictions and the calculated accuracy for each level.
- Email your results, including model details (name, size, type) and a link to your paper or project page, to our team.
Contact us for submission:
- Zhengyang Liang: zyliang@smu.edu.sg
- Yan Shu: yan.shu@unitn.it
Citation
@misc{liang2026videobrowseragenticopenwebvideo,
title={Video-Browser: Towards Agentic Open-web Video Browsing},
author={Zhengyang Liang and Yan Shu and Xiangrui Liu and Minghao Qin and Kaixin Liang and Nicu Sebe and Zheng Liu and Lizi Liao},
year={2026},
eprint={2512.23044},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.23044},
}